You’re mostly better off reading the book Clean Architecture by Robert C. Martin. But well, now that you’re here…
In the beginning,
there was programming. Instructions were punched into sheets and fed into machines one at a time.
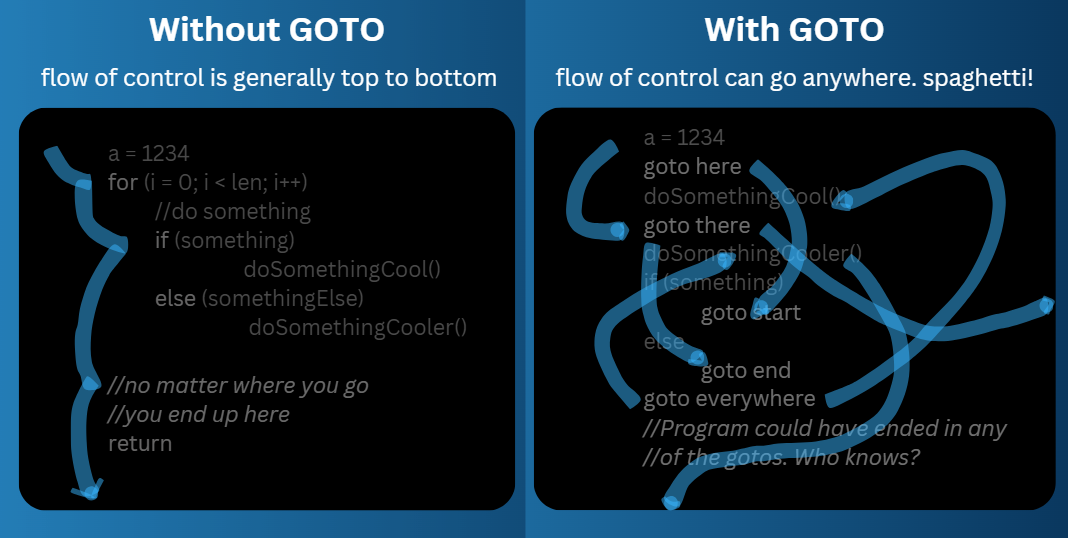
As typing programs became possible, a new approach called “structural programming” emerged. It involved writing programs as a sequence of instructions organized into blocks of code, incorporating control structures like loops, conditionals, and the infamous GOTO statements. A general way to understand how the program works is to start at the top and follow the flow of control (or order of execution).
GOTO
One major problem with the initial programming style was the GOTO statement; instead of the general flow of control (top to bottom), it allowed the programmer to jump to any other part of the program. Drawing a line through the program to follow the flow of control led to the line haphazardly jumping through the program which was difficult to visualize, all over the place - kind of like spaghetti. Hence the name “Spaghetti code”.
However, the GOTO statement was a powerful tool and in use by many programmers; the problems it posed were not immediately obvious. Dijkstra famously published a paper titled “GOTO statement considered harmful”, sparking heated debates.
Eventually the market decided the GOTO statement’s fate, with many programming languages either removing that support altogether (since the same results could be achieved using loops and conditionals) or limiting the scope of GOTO statements (like break or continue statements).
Imperative, Procedural programming
The programs were small and could mostly be understood by a single person. But as memory and computation capabilities increased, programs grew larger and complex, surpassing the capabilities of a single person to remember it all; it became difficult to reason about the flow of control.
This lead to usage of smaller “modules”, “procedures” or “functions” that abstracted away some of the implementation details - a set of steps to be followed by the computer was packaged in named blocks called functions. If it had to be used multiple times, the same function could be called instead of duplicating it repeatedly.
This was termed modular or procedural programming; generally, imperative programming.
Object Oriented Programming
Now that we had modules and procedures, there was the problem of actually managing those modules. A logical next step was to group related functions and data together into “objects” - a way to model real world entities.
This evolved some guiding principles of software development - encapsulation (grouping related info together), inheritance (easily extending functionality), polymorphism (ability to handle different inputs), etc. apart from access rules and so on enforced by the languages.
Declarative programming
In imperative programming, functions emerged as independent blocks of code that could be invoked or executed separately, a set of procedures to be followed.
The initial versions of databases like IBM IMS (Information Management System) and CODASYL (Conference on Data systems languages) used Imperative language as compared to Declarative language.
Let’s say we want to get all “sharks” from a list of animals - 'shark_great_white', 'bird_eagle', 'animal_lion', 'animal_hippo', 'shark_hammerhead', 'bird_sparrow':
|
|
The imperative language tells the computer to perform operations in a particular order. However, the computer can never be sure if the result depends on the ordering or not and thus cannot introduce major improvements.
The declarative language tells the computer the kind of result we need, not how to get it. It’s upto the computer to to decide order, indices, joins, etc. This enables it to implement performance improvements without breaking any queries and hides all implementation details.
|
|
We see declarative programming mainly in databases since the scope for optimization is huge and has concrete results.
|
|
Declarative code also lends itself to parallelization across cores or machines.
Imperative code is hard to parallelize, the computer does not know if running parts of the code in parallel will give a result different from the expected result.
Functional programming
A subset of Dynamic programming - the concept of treating functions as first-class citizens instead of blocks that can only be executed emerged, enabling functions to be passed as arguments, returned from other functions, and more - similar to constants or variables.
Even the example for declarative code uses functional programming - the argument in filter(animal => animal.contains('shark')) is a function.
Some rules are introduced to make it easier to reason about the code and perform optimizations (like making it possible to run it in parallel):
functions are pure where possible (a function with an input always returns the same output), no side effects (like modifying a variable outside the function), variables are immutable (cannot be modified haphazardly) etc.
Certain functional languages like Haskell enforce this strongly - that they do not allow modifying a variable outside the function at all.
This promotes referential transparency, which means that a function call can be replaced by its computed value without affecting the program’s behavior; just like math, where if x = 2, x + 1 = 3 and 2 + 1 = 3 are equivalent.
What have we learnt?
Imperative programming removes GOTO, limiting our ability to directly jump to parts of the programs easily.
Object oriented programming takes away unrestricted transfer of control from one module to another with rules like abstraction, encapsulation, etc.
Declarative programming restricts our ability to modify variables by making them immutable.
Funtional programming takes away side effects, making it difficult to modify variables outside the function for our use.
Considering that functional programming was done in the ’50s and Dijkstra’s paper came out in the ’60s, I quote from Uncle Bob’s Clean Architecture - every “restriction” has enabled us to write better code:
Each restricts some aspect of the way we write code. None of them has added to our power or our capabilities. What we have learned over the last half-century is what not to do.
With that realization, we have to face an unwelcome fact: Software is not a rapidly advancing technology. The rules of software are the same today as they were in 1946, when Alan Turing wrote the very first code that would execute in an electronic computer. The tools have changed, and the hardware has changed, but the essence of software remains the same.
Software—the stuff of computer programs—is composed of sequence, selection, iteration, and indirection. Nothing more. Nothing less.